AI Summary
- Started with Ansible for a simple server setup, ended up building a complete AI deployment solution
- Docker configuration complexity led to creating an intelligent setup script that handles everything
- Built for anyone who wants a local AI server without the deployment headaches
- One script deploys LocalAI, Ollama, Stable Diffusion Forge with automatic GPU detection
The Accidental Project
I was setting up another AI server. Not my first rodeo - I’ve done this dance before. Multiple GPUs, Docker containers, NVIDIA drivers, the usual suspects. But this time I thought, “Let me try Ansible, make it reusable for next time.”
Two days and one very long night later, I emerged from a coding fugue with a complete deployment solution that I never intended to build.
This is the story of how a simple automation attempt spiraled into AI Box - and why sometimes the best projects are the ones you stumble into.
When Simple Tasks Attack
The plan was straightforward: write some Ansible playbooks, deploy services, done by lunch. But if you’ve ever tried to deploy GPU-accelerated Docker containers, you know it’s never that simple.
The Docker documentation for GPU support is… mixed would be generous. What should have been a simple configuration turned into hours of tinkering:
|
|
But then you discover:
- The NVIDIA runtime needs specific configuration
- GPU device mounting has changed three times in recent Docker versions
- Environment variables behave differently across container images
- Each service has its own special GPU requirements
What started as “let me properly configure this” became “let me abstract away all this pain forever.”
The Evolution of Complexity
Here’s how the project evolved from simple to sophisticated:
Hour 1: The Ansible Dream
|
|
Hour 8: The Bash Pivot
After fighting with Ansible’s Docker modules and realizing I’d need custom logic everywhere, I pivoted to a shell script. But not just any shell script - one that wouldn’t destroy existing work:
|
|
This single function represents a philosophy shift. Instead of the typical “destroy and recreate” approach, it respects existing work. Because who hasn’t accidentally nuked their carefully curated model collection?
The GPU Detection Breakthrough
Getting GPU assignment right was crucial. The script needed to work on everything from a single-GPU laptop to our 8-GPU inference servers:
|
|
The clever bit? It uses nvidia-smi if drivers are installed, but falls back to lspci for fresh systems. This means the script works even on a brand-new Ubuntu installation.
Why These Services?
The modern AI stack selection wasn’t random:
LocalAI: True OpenAI API compatibility means existing code just works Ollama: Dead-simple model management -
ollama pull llama2and you’re done
Forge: Next-gen Stable Diffusion interface with better performance than A1111
Each represents best-in-class for its purpose. No legacy baggage, no unnecessary complexity.
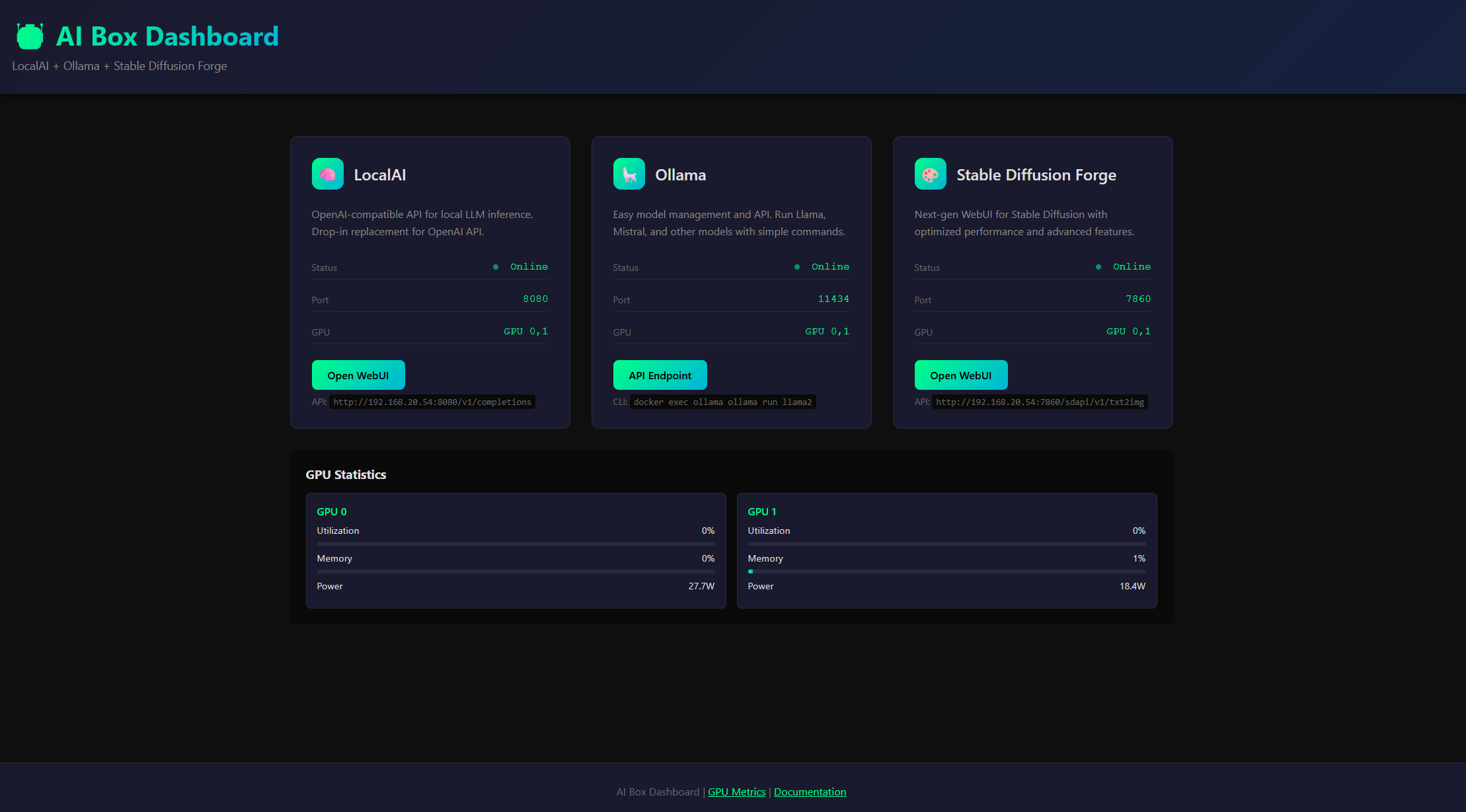
The Dashboard: Making It Visual
Late into that long night, I had services running but checking on them meant SSH and docker commands. “Just a simple status page,” I thought at 2 AM.

The dashboard provides:
- Real-time GPU metrics: See utilization and memory usage at a glance
- Service status indicators: Know what’s running without SSH
- Quick access links: Jump directly to any service interface
- Dynamic server detection: Works from any machine on your network
The technical challenge was interesting. Browser CORS policies prevent direct health checks to services, so I used a pragmatic approach:
|
|
Not perfect, but functional - and at 3 AM, functional wins.
Ollama: The API Gateway Drug
One service deserves special attention. Ollama has become my go-to for quick LLM integration into workflows. The API is beautifully simple:
|
|
I’ve integrated this into:
- Shell scripts: Quick analysis of log files or code
- Python workflows: Automated report generation
- Home Assistant: Natural language control of my smart home
- VS Code: Custom AI assistance without cloud dependencies
The beauty is the simplicity. No API keys, no rate limits, no privacy concerns. Just point your code at the Ollama endpoint and go.
The Reboot Philosophy
One design decision I’m particularly proud of: no automatic reboots.
|
|
Production systems can’t randomly reboot. The script saves its state, exits cleanly, and resumes exactly where it left off after you manually reboot. It’s a small thing, but it shows respect for the operator’s control.
Lessons from the Rabbit Hole
Building AI Box taught me several things:
1. Start with the user experience, not the technology The script asks what you want instead of assuming. This simple change prevents so much frustration.
2. Perfect is the enemy of deployed The dashboard CORS issue could have killed the project. Instead, I accepted a pragmatic workaround and moved on.
3. Respect existing work The idempotent design means you can run the script 100 times without fear. This builds trust.
4. Sometimes “good enough” is perfect Could I add more error handling? More dynamic features? Sure. But right now it solves the problem it set out to solve.
Where It Stands
AI Box is at a good stopping point. It does what it promises: gets you from zero to a working AI server with minimal pain.
The script handles:
- Any number of GPUs (tested up to 8)
- Fresh or existing installations
- Driver installation and reboot workflows
- Service deployment and configuration
- A functional dashboard for monitoring
Future me might add more error handling, make it more dynamic, support more services. But current me knows that shipped code helping people today beats perfect code helping nobody tomorrow.
Try It Yourself
If you’re tired of manually configuring AI services, give it a shot:
|
|
In about 10 minutes, you’ll have a fully operational AI server with a nice dashboard to monitor it all. No Ansible required.
Final Thoughts
Sometimes the best projects are accidents. I set out to automate something I’d done before and ended up with a solution that’s already saved me hours on subsequent deployments.
AI Box isn’t revolutionary. It’s just a script that handles the annoying parts of AI server deployment. But after setting up AI servers the hard way multiple times, “just works” feels revolutionary enough.
The code is on GitHub. Feel free to use it, improve it, or just steal the parts that solve your specific problems. After all, the best code is the code you don’t have to write.
Now if you’ll excuse me, I have some models to download. That Ollama API isn’t going to integrate itself into my latest workflow experiment.